已创建阿里云RDS MySQL 5.6实例,数据库可用空间大小要有AWS
RDS显示的数据大小的2倍以上(因为导入数据库时产生的Binlog,后续会自动清理掉的)。
AWS RDS创建:https://www.hkt4.com/zt/2023-05-06/
设置 AWS RDS 使用外网地址访问,操作步骤如下所示:
打开AWS RDS Console, 进入要迁移实例的Dashboard页面。记下group id (红框部分),然后在页面左边单击Security
Groups。
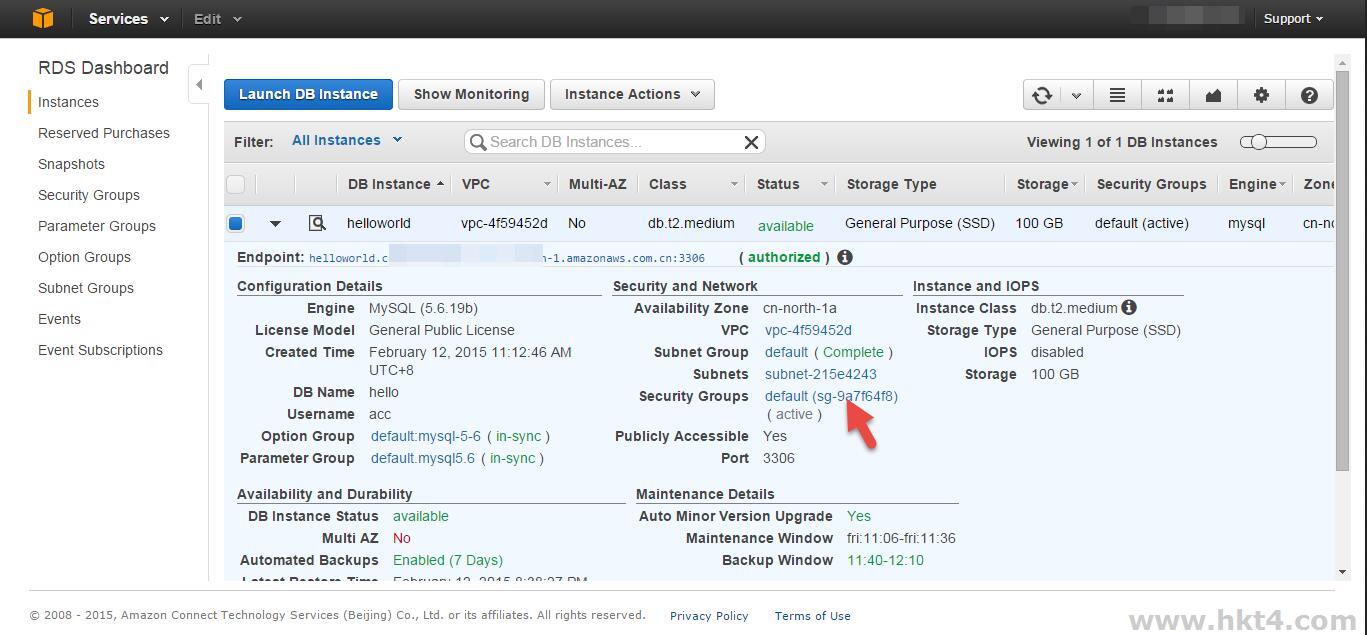
在Security Group页面选择相应的group,红框部分对应第一步的group id。选择Inboud选项卡,单击Edit按钮。
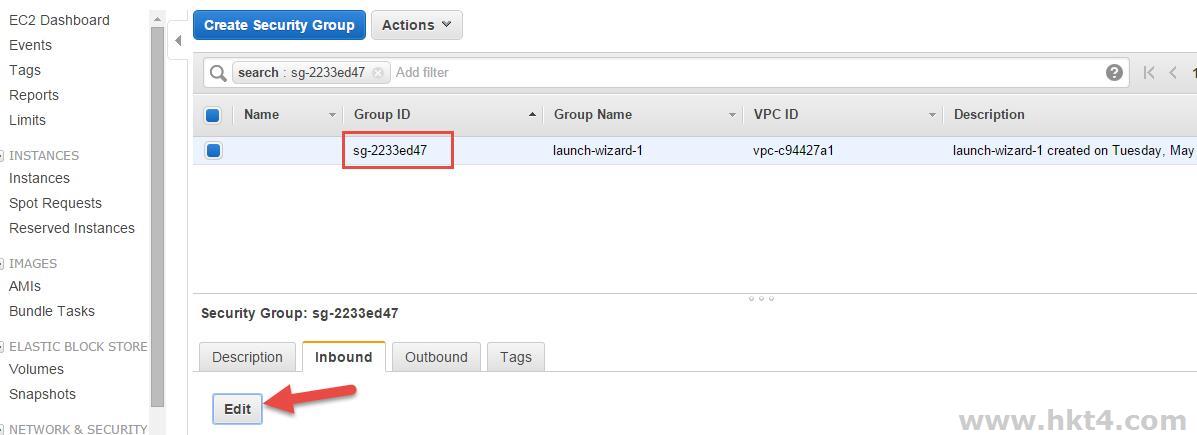
在弹出对话框中,Type下拉列表中选择MySQL,Source下拉列表中选择Anywhere,单击Save按钮。
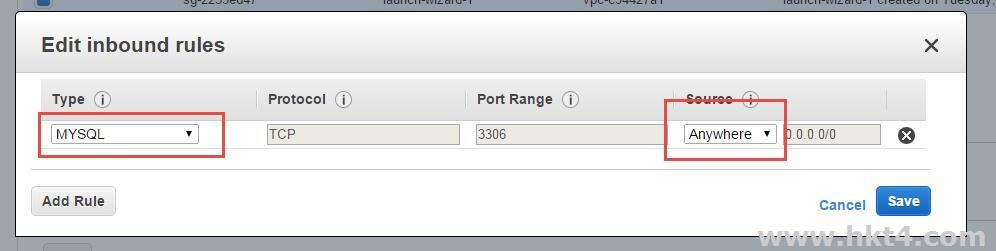
获取数据库IP地址,回到AWS RDS实例页面,选取并复制数据库地址(Endpoint)。
创建阿里云RDS帐号,操作步骤如下所示:
登录 RDS 管理控制台,选择目标实例。
选择菜单中的账号管理,单击创建账号,如下图所示。
输入要创建的账号信息,单击确定,如下图所示。
数据库账号:由2~16个字符的小写字母,数字或下划线组成、开头需为字母,结尾需为字母或数字。
密码:该账号对应的密码,由6~32个字符的字母、数字、中划线或下划线组成。
确认密码:输入与密码一致的字段,以确保密码正确输入。
备注说明:可以备注该账号的相关信息,便于后续账号管理,最多支持256个字符(1个汉字等于2个字符)。
创建阿里云RDS数据库,操作步骤如下所示:
选择菜单中的数据库管理,单击创建数据库,如下图所示。
输入要创建的数据库信息,单击确定,如下图所示。
数据库(DB)名称:由2~64个字符的小写字母、数字、下划线或中划线组成,开头需为字母,结尾需为字母或数字。
支持字符集:设置数据库的字符集:utf8、gbk、latin1和utf8mb4。
授权账号:选择该数据库授权的账号。如果尚未创建账号,该值可以为空。
账号类型:选择授权账号后可见,设置该数据库授权给授权账的权限,可以设置为读写或者只读。
备注说明:可以备注该数据库的相关信息,便于后续数据库管理,最多支持256个字符(1个汉字等于2个字符)。
使用DTS进行数据迁移,操作步骤如下所示:
打开DTS控制台,单击数据迁移页签,如下图所示:
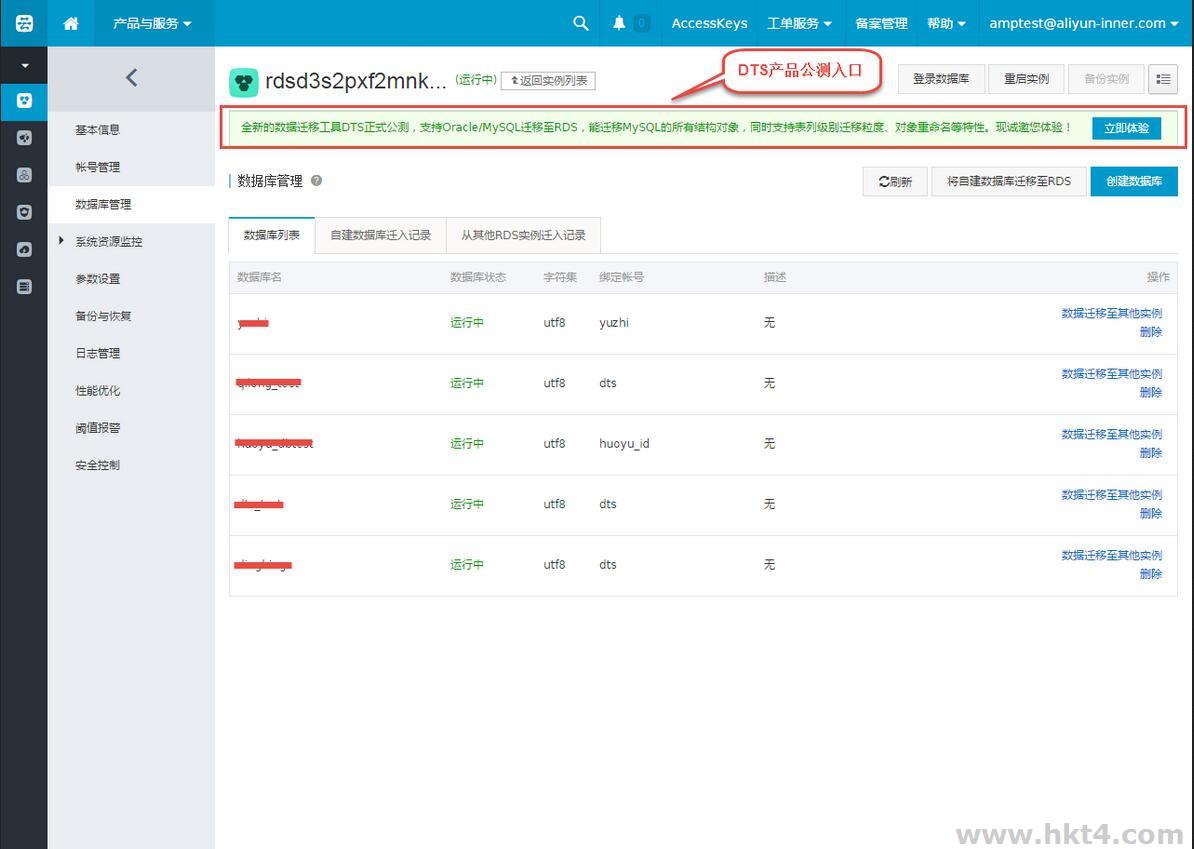
单击创建迁移任务,进入任务配置页面,填写源库信息和目标库信息,如下图所示。
源库连接信息:源库实例类型选择有公网IP的自建数据库,填写对应的源库连接信息。
目标库连接信息:目标实例类型选择RDS实例,填写对应的目标库链接信息。
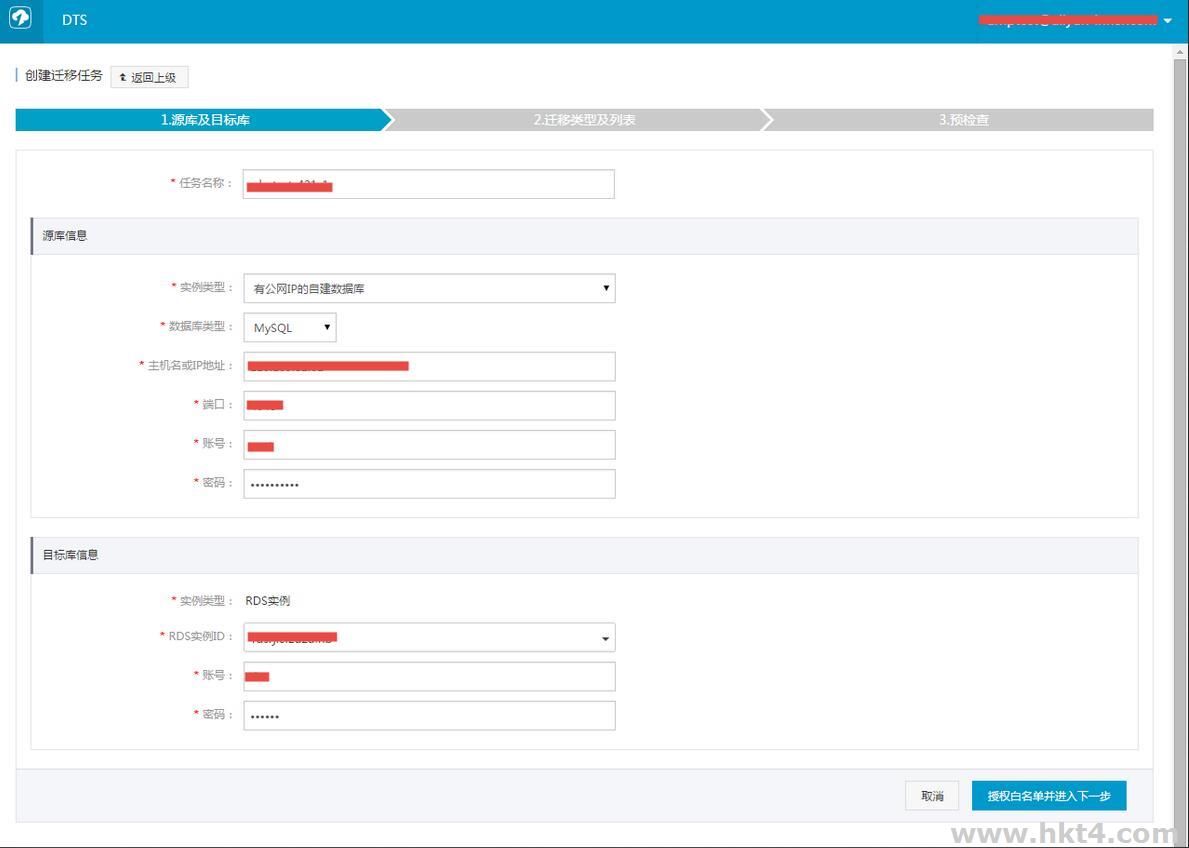
选择要迁移的对象列表,以及迁移的类型,如下图所示:
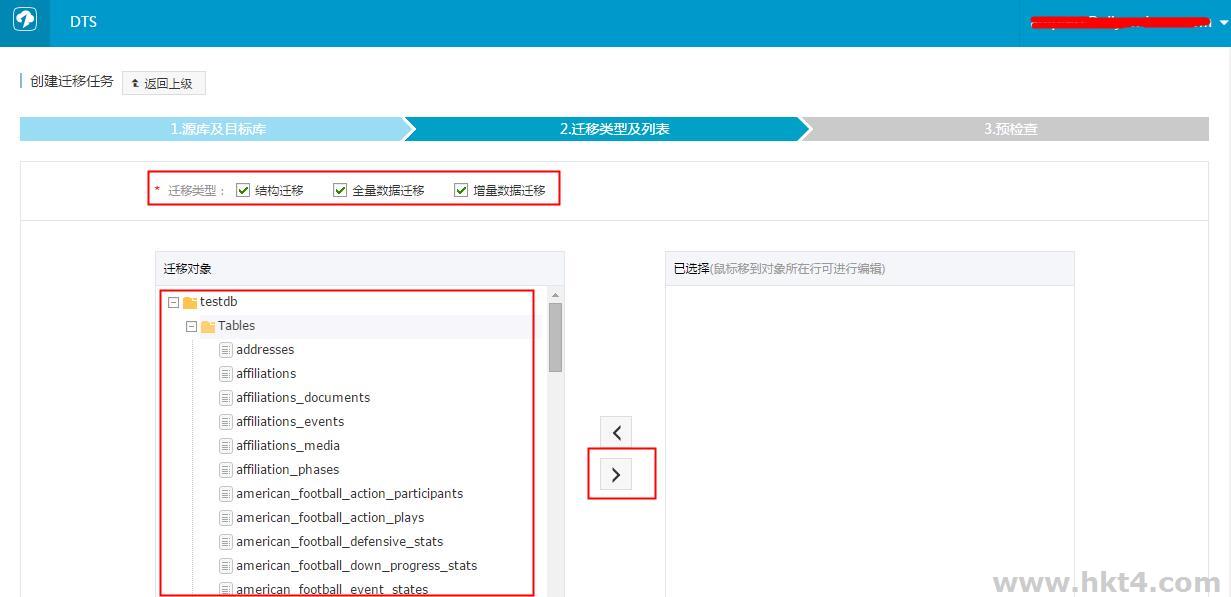
说明:
如果源库应用在迁移过程中有更新,那么可以选择进行增量数据迁移。在左边的迁移对象框中,选择需要迁移的对象,并拖动到右边的选择框中。
如果用户的阿里云RDS上的数据库同AWS上的库名不一致,或者需要修改表名,那么可以在右边已选择对象中单击编辑进行修改。如下图所示:
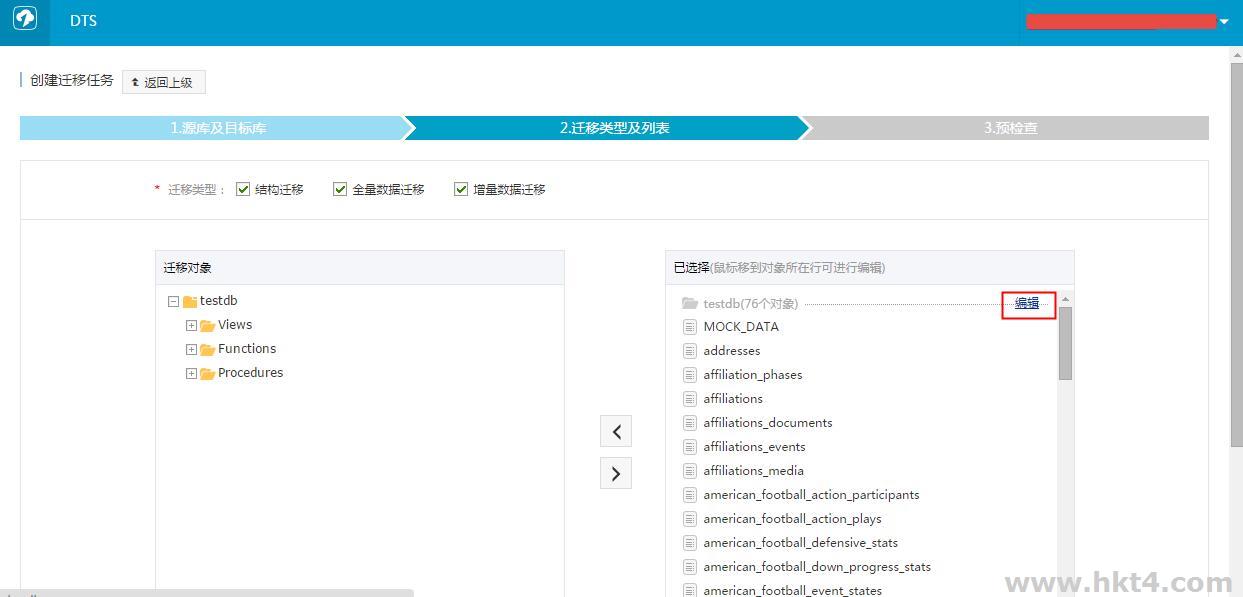
单击编辑按钮,进入编辑页面,可以将数据库名修改成目标库数据库的库名。如下图所示:
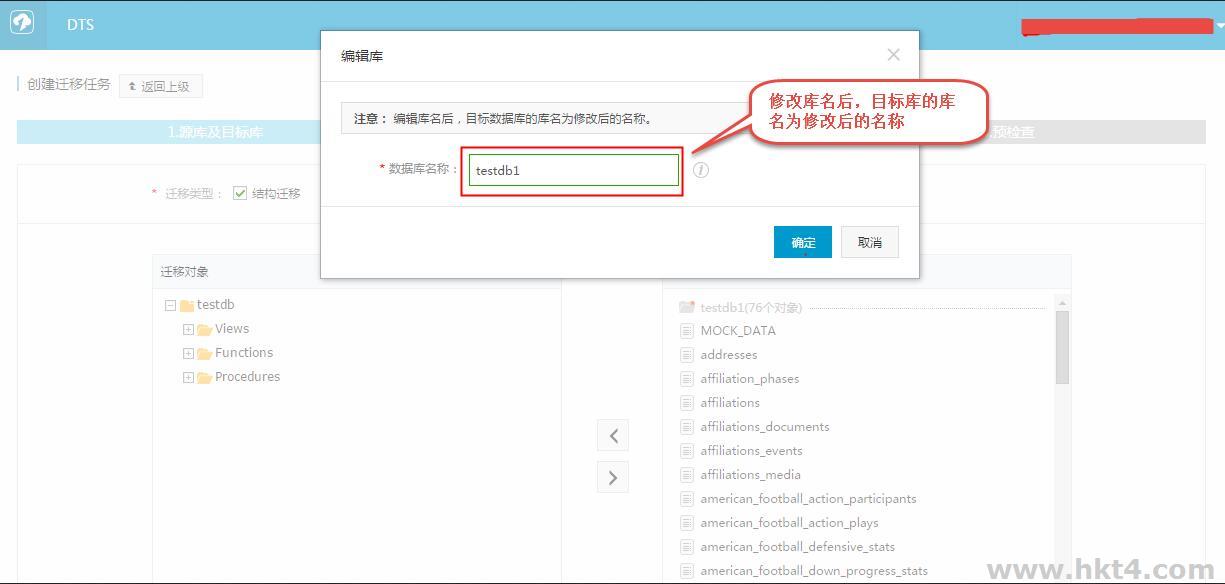
单击保存,保存之后单击预检查并启动,进入任务预检查。如下图所示:
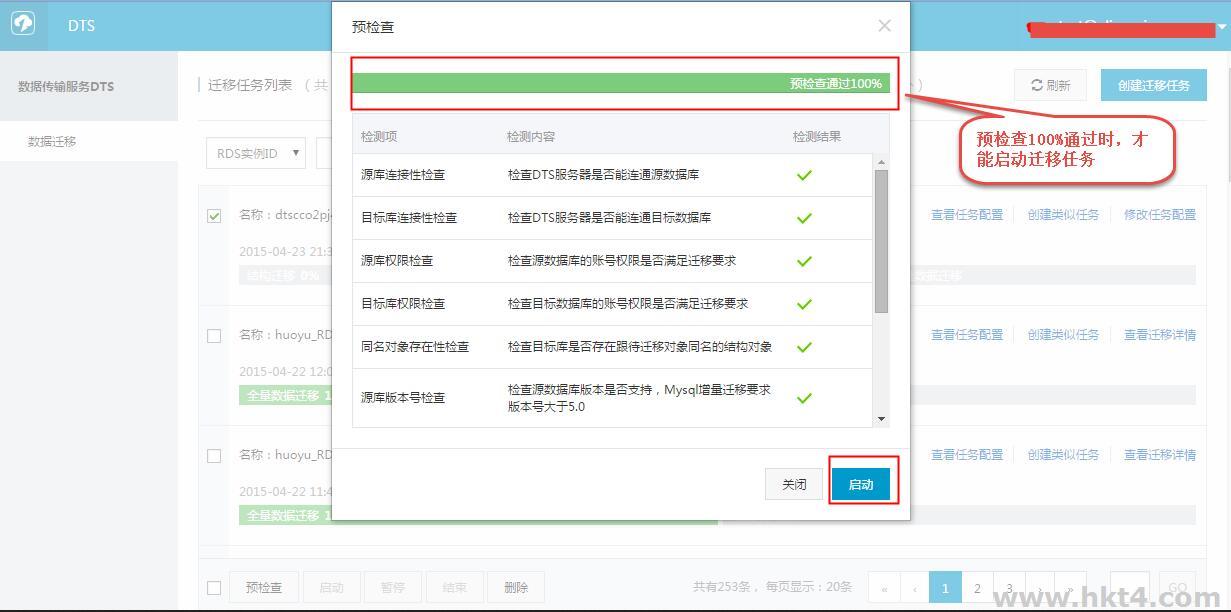
当预检查成功后,单击启动,任务即启动,可以在任务列表查看任务进度状态。如下图所示:
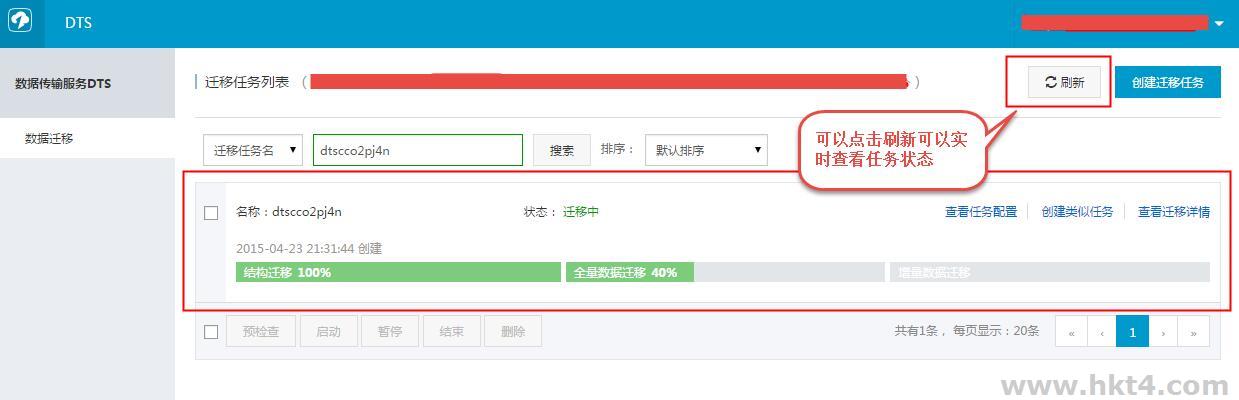
说明:当增量迁移无延迟时,AWS和阿里云RDS上面的数据一致,可以停止迁移任务。
注意:由于AWS会尽最快的速度回收binlog,而增量迁移依赖源库的binlog日志,所以为了防止未被增量同步的binlog日志被清除掉。可以调用AWS
RDS的存储过程
来设置binlog的保存时间。例如将保存时间延长至一天,调用这个存储过程的命令为:

AWS数据迁移到阿里云的一些坑
只读RDS修改配置组无效果
我们这一次数据库的迁移是重点任务,考虑到AWS的源库都是无公网访问权限的,于是就创建一个有公网权限的只读库(read
replica),然后在阿里云是用DTS,以这个只读库作为源库,然后进行数据的增量同步。这里有一点:“源库”的binlog必须是ROW模式,而默认的AWS创建的源库是MIX模式,于是就需要修改一下参数组(parameter
group),将其改成ROW:
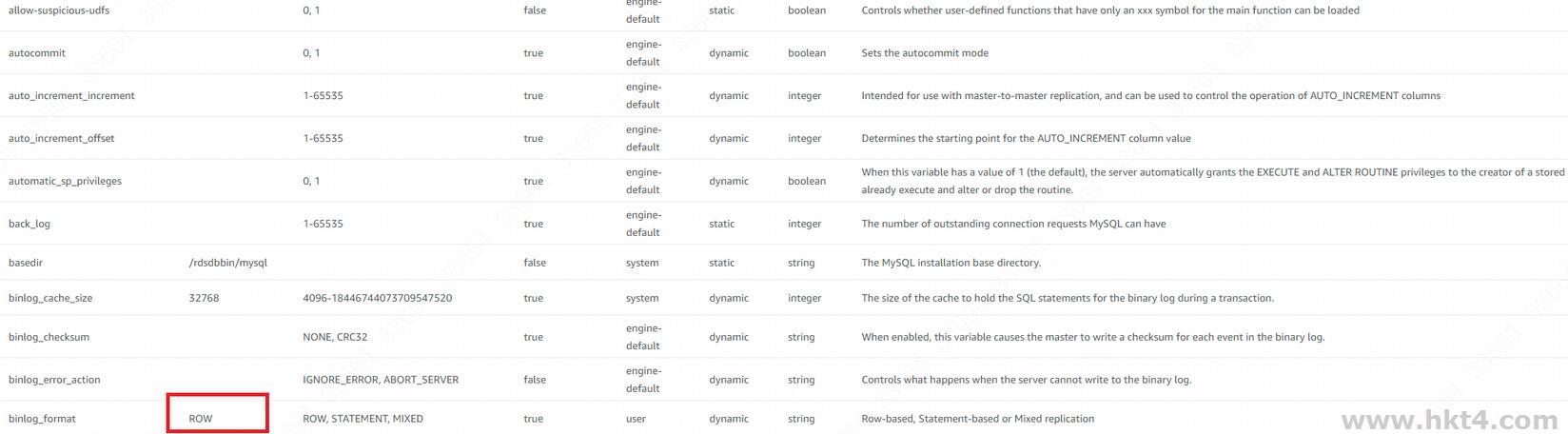
然后配置只读实例引用这个参数组,但是要等待参数组状态是(pending reboot),重启。
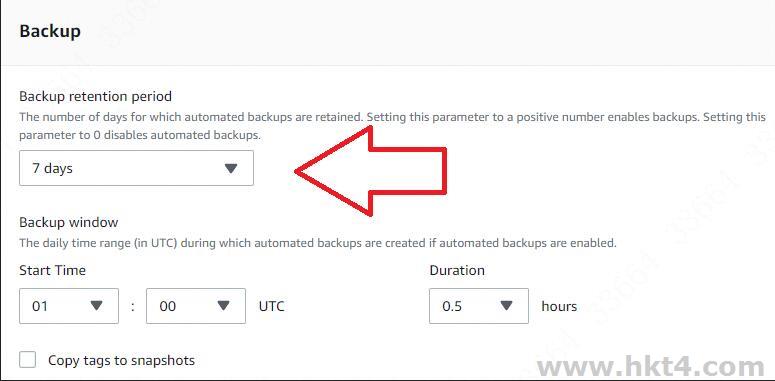
但是这里有一个大坑!那么就是read replica的Backup retention
period值不可以是0,不然参数组即使重启了是不会生效的!
当然直接使用DTS并不是一个好方案,因为即使是同一个可用区,比如都在法兰克福,但是不同厂商还是会有网络影响,所以更加推荐就是搭一个专线,然后走专线同步。而且DTS的时候,切忌目标库发生与源库不同的操作造成数据错乱,那样就前功尽弃了。
DTS的原理就是不断的读取binlog然后执行binlog,但是row模式的binlog特别巨大,再加上网络有波动或者源库有跟主库名称一样但是内容不一致的数据导致所有唯一主键都要报错一遍,那么延迟可能就是一辈子的事儿…
无公网ec2访问外网
本次迁移数据除了mysql还有redis,但是AWS的redis也都是内网服务器,于是这样我们就做了外网NLB,在阿里云的redis上做主从配置,并且在阿里云的redis.conf里把主写成了NLB的域名,这里如果担心NLB域名后面的IP发生变化而故障,那么可以事先在aws里购买弹性IP,然后将域名绑定死对应的IP就不怕了。
但是如果想要返回来,让阿里云的redis做主,AWS这个无公网的ec2
redis做从的话,用外网NLB就不行了。不过AWS比较好,就是ec2虽然表面没有公网IP,但是它有一个隐藏的公网,比如我这个ec2:

可见它没有公网IP,但是在服务器里使用curl myip.ipip.net可以获取到它的公网出口IP:

将这个IP写到阿里云的安全组就可以在ec2这边访问到阿里云的公网了!
DMS白名单问题
AWS的数据迁移叫DMS,这个地方也有一个坑,就是Replication instances的公网IP可能是不对的,如图:

我把图中的Public IP
address填写到了阿里云对应数据库的白名单里但是test无法成功,后来改成0.0.0.0/0之后登陆上去一看,连接的IP并不是图中的IP,这真的是一个大坑!







